Le monde numérique évolue vite, et avec lui, le volume de données collectées ne cesse d’augmenter. Des milliards de capteurs connectés, issus de l’iot (internet des objets), transmettent en continu une masse impressionnante d’informations. Jusqu’à récemment, la tendance favorisait encore le cloud computing pour centraliser et traiter ces flux. Mais aujourd’hui, l’informatique en périphérie – ou edge computing – gagne du terrain, bouleversant les habitudes. Naviguer au cœur de cette architecture décentralisée permet de mieux saisir pourquoi elle s’annonce comme un acteur majeur dans le futur du traitement des données.
Qu’est-ce que l’edge computing ?
L’edge computing désigne un mode de traitement local des données qui consiste à rapprocher la puissance de calcul au plus près de leur source. Plutôt que d’envoyer systématiquement toutes les informations vers un centre distant, les dispositifs déployés sur le terrain analysent et filtrent directement ce qu’ils captent.
Ainsi, l’architecture décentralisée offerte par l’informatique en périphérie limite la charge du réseau, réduit le volume des transferts de données et ouvre la voie à des réactions quasi instantanées. Les sites industriels, villes connectées ou véhicules intelligents exploitent déjà ce principe pour accélérer la prise de décision.
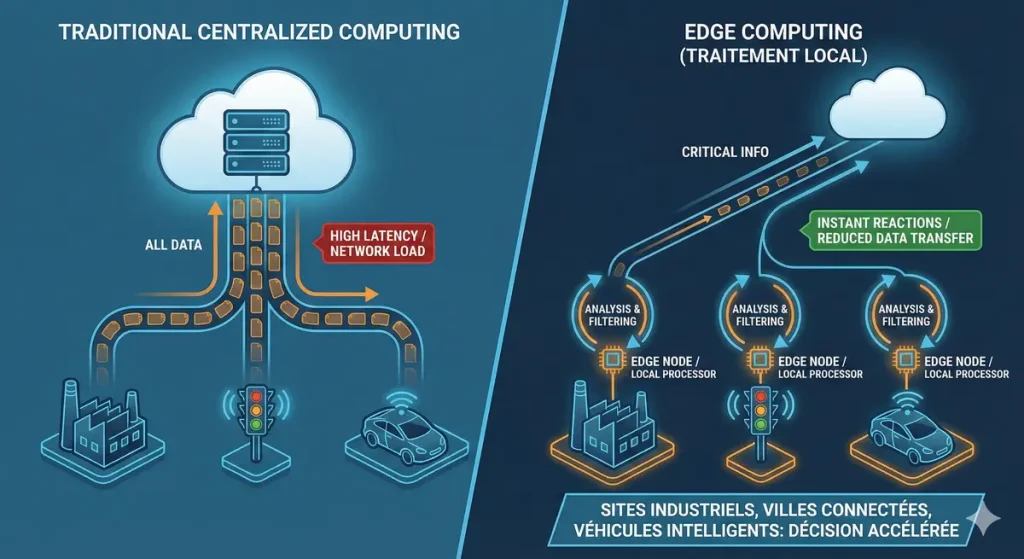
Pourquoi l’edge computing révolutionne-t-il le traitement des données ?
Certaines situations demandent de réagir sans délai. Entre un capteur détectant une anomalie critique et la conséquence de cette alerte, chaque milliseconde compte. L’edge computing permet alors de réduire drastiquement la latence, offrant la possibilité d’agir immédiatement grâce au traitement local.
En rendant possible l’analyse des données en temps réel juste là où elles sont produites, cette approche améliore la performance globale et diminue la dépendance vis-à-vis des serveurs centraux. Elle favorise aussi la confidentialité, car seules les informations pertinentes remontent vers le cloud ou les centres de commande.
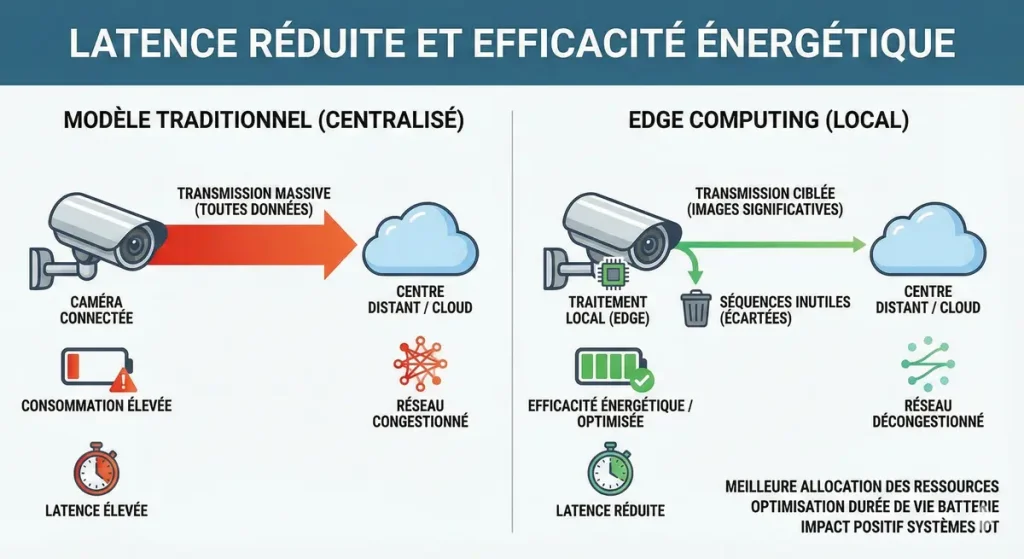
Latence réduite et efficacité énergétique
La rapidité de réponse n’est pas le seul atout : le fait de traiter une partie des informations localement réduit les besoins énergétiques liés aux transmissions massives. Une caméra connectée, par exemple, peut ainsi écarter immédiatement les séquences inutiles et ne transmettre que les images significatives.
Ce fonctionnement favorise donc une meilleure allocation des ressources, limitant la congestion du réseau tout en optimisant la durée de vie des équipements alimentés sur batterie. Cela a un impact direct sur l’efficacité des systèmes iot répartis dans de nombreux environnements.
Sécurité et confidentialité renforcées
Grâce à l’edge computing, la sécurité des systèmes bénéficie aussi d’un niveau supplémentaire de protection. Comme les informations sensibles restent souvent traitées sur place, le risque qu’elles soient interceptées lors d’un transfert vers un cloud public diminue fortement.
Pour les infrastructures critiques ou les secteurs soumis à de fortes contraintes réglementaires, conserver le contrôle sur le traitement local représente une avancée notable. Ainsi, les applications de santé ou de gestion urbaine tirent parti de cette capacité à garder les données confidentielles sur site tout en permettant une exploitation intelligente via l’ia.
Quel avenir pour l’edge computing dans la gestion des données ?
Le développement rapide de l’intelligence artificielle (ia) accentue le besoin d’un traitement des données performant et réactif. Pour entraîner ou exploiter des modèles issus de l’ia, il devient parfois indispensable de disposer de capacités analytiques sur place. L’intégration de l’ia dans l’edge computing offre ainsi de nouvelles possibilités : surveillance prédictive, maintenance proactive, ou optimisation énergétique.
À mesure que le nombre d’appareils connectés explose, cette approche décentralisée devrait poursuivre son essor. Les infrastructures 5G et les technologies émergentes faciliteront également l’implantation généralisée de l’informatique en périphérie, ouvrant la porte à toujours plus de services personnalisés et sécurisés.
Quelle est la différence entre edge computing et cloud computing ?
Le cloud computing centralise les ressources de calcul et de stockage dans de grands datacenters distants, alors que l’edge computing positionne ces capacités directement à la périphérie du réseau. Cette distinction influence la rapidité d’exécution, la gestion de la bande passante et l’exposition aux attaques potentielles.
| Caractéristiques | Edge computing | Cloud computing |
|---|---|---|
| Lieu du traitement | À proximité des sources de données | Centres de données distants |
| Temps de réponse | Très faible | Variable |
| Bande passante | Optimisée | Peu optimisée |
| Sécurité | Renforcée localement | Dépendante du réseau |
Quels sont les avantages principaux de l’informatique en périphérie ?
- Latence réduite pour des réactions quasi instantanées
- Diminution du volume de données envoyé vers le cloud
- Meilleure confidentialité et sécurité locale des données
- Efficacité énergétique accrue
Ces bénéfices rendent le traitement local particulièrement utile dans l’iot, les systèmes industriels ou les applications nécessitant des réponses rapides.
Quels sont les défis à relever pour généraliser le traitement des données en périphérie ?
Mettre en place une solution d’architecture décentralisée impose de garantir la fiabilité des appareils, la gestion cohérente des mises à jour logicielles et l’interopérabilité. La sécurisation des communications locales reste également essentielle pour éviter d’exposer des points faibles supplémentaires.
- Maintenance distribuée
- Protocoles d’échange compatibles
- Mises à jour automatiques fiables
- Détection avancée des failles de sécurité
L’edge computing va-t-il remplacer totalement le cloud computing ?
Plutôt que de remplacer définitivement le cloud, l’informatique en périphérie agit comme un complément optimisant le traitement des données selon le contexte. Les entreprises combinent souvent ces deux approches pour bénéficier à la fois de la puissance centralisée du cloud et de la réactivité permise par le traitement local.
- Systèmes hybrides fluidifient la circulation et l’analyse des données.
- Applications sensibles bénéficient simultanément de capacité décentralisée et de stockage sécurisé massif.

Rédacteur Web et passionné de technologies
Passionné de nouvelles technologies et très positif, je rédige pour le web depuis des années déjà. Surtout pour des contenus Tech et Web ainsi que les nouvelles tendances. J’adore partager mes trouvailles et divertir mes lecteurs avec des contenus riches et intéressants.

Comment fonctionne une architecture décentralisée ?
Derrière l’edge computing se cache une organisation technique précise, articulée autour de plusieurs niveaux de traitements.
L’informatique en périphérie ne remplace pas totalement les stratégies existantes, mais vient en complément pour choisir, en fonction du contexte, si le traitement immédiat suffit ou si une synchronisation différée reste préférable.
Comparaison entre edge computing et cloud computing
Tandis que le cloud computing repose sur d’immenses datacenters gérant simultanément des millions d’opérations, le modèle décentralisé de l’edge pousse le calcul plus près du terrain. Cette distinction joue un rôle essentiel dans les domaines où chaque milliseconde est cruciale ou lorsqu’une connexion fiable n’est pas garantie.
Dans certains cas, une combinaison des deux modèles s’avère judicieuse. Les tâches non urgentes ou nécessitant une forte puissance de calcul peuvent encore être confiées au cloud, tandis que l’essentiel du filtrage, de la réaction ou de l’ajustement s’effectue « en bordure » du réseau.
Cas d’usage concrets et avantages
De l’automatisation industrielle à la gestion du trafic urbain, les exemples foisonnent. Grâce à la latence réduite, un système de vidéosurveillance connecté peut identifier rapidement un comportement inhabituel avant même que l’alerte arrive en centre de supervision. Dans l’automobile, le traitement local garantit des réactions instantanées face à un obstacle imprévu.
L’iot profite pleinement de cette technologie grâce à sa souplesse. Ce paradigme booste également des secteurs comme la logistique, où prévoir une rupture de chaîne ou anticiper des défauts techniques fait toute la différence.